最近学后缀数组,需要接触到这些排序方法,于是乎开帖记录。
术语说明
本文中,“排名”可以粗浅地理解为“不大于的元素个数称为的排名”。但是,有重复元素的时候,假设小于的元素个数是,不大于的元素个数是,那么这些重复元素的排名各不相同,且都位于区间中。
如,数组中各元素的排名可以是,当然也可能是等等。
本文中要大量使用“元素数组”、“排名数组”这样的词汇,请牢记它们的含义:叫做什么数组,里面存的就是什么值。
- “元素数组”指根据排名查元素编号的数组,即
- “排名数组”指根据元素编号查排名的数组,即
这两个数组之间是逆映射的关系。
在桶排序中,还会用到桶数组。桶数组是根据元素值查“这个值的元素有多少个”的数组,做前缀和后就是根据元素值查“不大于这个值的元素有多少个”的数组。通常,我们使用它的后一种含义。
- “桶数组”是根据元素值查“不大于这个值的元素有多少个”的数组,即
熟悉这些映射关系,对于快速写出代码有很大帮助。
文中还用了 Pascal 的数组区间符号。a[1...3]={1,2,3}表示a[1]=1,a[2]=2,a[3]=3。
离散化
首先我们通过复习离散化方法,熟悉“元素数组”和“排名数组”的意义。
1 | int a[MAXN]; //原始数据 |
上述代码执行后,rk数组中的值就是离散化目标值。
桶排序
单关键字桶排序
桶排序?这个谁不会啊?
1 | int a[MAXN],bucket[MAXM]; //原始数据, 桶(桶的定义域是原始数据的值域) |
但是如何用桶排序求出元素数组和排名数组呢?这里介绍一种简单的办法。
我们知道,原始的桶数组记录的是“值为的元素的个数”。如果对桶数组做前缀和,记录的就是“值不大于的元素个数”——不就是“值为的元素的(最大)排名”吗?之所以是“最大”,是因为可能有重复元素(参见“术语说明”)。于是,我们可以用这种方法得到元素数组和排名数组。
下面这段代码对于理解多关键字桶排序比较重要,请认真阅读。如果对代码不太理解,请接着阅读下面的说明。
1 | int a[MAXN],bucket[MAXN],ele[MAXN],rk[MAXN]; |
现在问题来了,为什么这个循环是倒序的呢?也就是说,我们需要搞清楚,排名的“分配原则”是什么。同时我们还要搞懂这行关键代码:ele[ bucket[a[i]]-- ]=i;
首先,如果数组中没有重复元素,那么bucket[a[i]]只会被访问一次,其中的值正是i号元素的真正排名。
但如果数组中有重复元素呢?举个例子,如果a[1...6]={1,4,3,1,3,2},那么在求前缀和之前,bucket[1...4]={2,1,2,1};求前缀和之后,bucket[1...4]={2,3,5,6}。那么,的“最大排名”是,的“最大排名”是。
我们倒序循环分配排名。首先i=6,ele[ bucket[a[6]]-- ]=6。执行语句时bucket[a[6]]=bucket[2]=3,于是我们得到了号元素的排名是,也就是被赋予了排名的元素是号(ele[3]=6)。根据--运算符的规则,我们把bucket[2]的值减,那么执行后bucket[2]=2。这表示,排名已经被占用了,下一个值为的元素只能使用排名——当然,由于数列中只有一个元素的值是,因此不存在所谓的“下一个元素”。
接着i=5,ele[ bucket[a[5]]-- ]=5。bucket[a[5]]=bucket[3]=5,那么这次我们把排名赋给a[5]。这时bucket[3]--,表示下一个值为的元素只能使用排名——在这里就表示,靠前的一个将使用排名。
继续模拟这个过程,最后ele[1...6]={1,4,6,3,5,2}。在模拟的过程中我们发现,值相同的元素,先者总是得到较大的排名。就有些像孔融让梨,孔融是把大的梨让出去,先拿到排名的元素是把靠前的排名让给后拿到排名的元素。
而我们倒序循环,原本靠后的元素将先得到排名,结果就是值相同的元素,原本靠后的,排名也较大(即在排序后的数组里也靠后)。这正满足了“稳定性”的定义——这样它就是“稳定排序”了。
当然,这么做的意义远不止如此,正是这一操作,为桶排序提供了可扩展性。请看——
多关键字桶排序
什么叫“多关键字”呢?就有点像中考成绩排序——先按总分等级排序,总分等级相同的再按A+数排序,A+数相同的……概括地说,就是,优先按第一关键字排序,如果第一关键字相同,再按第二关键字排序。
下面我们只讨论两个关键字的情形;在此基础上,很容易扩展出更多关键字的排序。
还记得上面讲的“稳定性”吗?我们有一个思路——先按第二关键字排序,再按第一关键字做稳定排序。
为什么先排次要关键字呢?可以这么理解——第一次排序的结果会被第二次排序打乱,因此是次要的。第一次排序只是为了第二次排序在关键字相同时,提供原先的相对位置。也就是,第一次排序的功效,体现在了排序前相对位置上。
那么我们就可以写出多关键字桶排序的代码了。
1 | int a[MAXN],b[MAXN];// a 为主要关键字, b为次要关键字 |
整段代码最难理解的应该就是ele[bucket[a[ele_b[i]]]--]=ele_b[i];这一行了。足足四层嵌套,让不少多关键字桶排序和基数排序的初学者望而生畏。下面我们解析它。
对b做排序的时候,我们已经写过一次三层嵌套了。ele_b[ bucket[b[i]]-- ]=i;,意思是bucket[b[i]]中存着b[i]的排名,那么排名为bucket[b[i]]的元素编号就是i。
对a做排序的时候,我们不是要按ele_b[n],ele_b[n-1],...,ele_b[1]的顺序做嘛——于是,运用换元法,把ele_b[i]带入原来的i中,不就得到了这一行代码吗?
于是,双关键字的桶排序就写好了。这也就是这道题的解法。
基数排序
基数排序其实就是多关键字的桶排序。比如,给三位数排序,第一关键字是百位,第二关键字是十位,第三关键字是个位。
但实际操作中,我们所用的模数不是,而是的幂。根据挑战这道题的经验,我们取为模,把位整数(也就是int)分为四个关键字进行排序,分别排序四次就好了。
1 |
|
后缀排序
给后缀排序是建立后缀数组(Suffix Array)的关键操作。
字符串s[1...n]的后缀就是指这些子串:s[1...n],s[2...n],s[3...n],...,s[n...n]。按照后缀的起始点,分别把它们编号为。
“后缀排序”就是对这个后缀(就是个字符串)进行排序。当然不是真的排序,只是求出元素数组和排名数组罢了。
在这里重新强调元素数组和排名数组的定义:
- 元素数组,此处称作后缀数组或
sa数组,表示排名为i的后缀的编号是sa[i] - 排名数组,此处称作
rank(缩写为rk)数组,表示编号为i的后缀排名为rk[i]
还是那句话,“名副其实”,后缀数组里的东西是后缀(的编号),排名数组里的东西是排名。
如何给后缀排序呢?最简单的方法当然是直接应用一遍快速排序,时间复杂度是,足够快了吧。
可惜的是,这个时间复杂度是错的。由于比较两个字符串是而非的,快速排序需要次比较,因此正确的复杂度应该是,无法承受。
那么改成基数排序吧?字符串的排序是按照字典序,也就是以第一个字符为第一关键字、以第二个字符为第二关键字,以此类推。可是这样会有个关键字,需要(桶)排序次,每次排序的时间复杂度是,合起来达到,依然无法承受。
做不出来的时候怎么办?看看我们是不是漏条件了啊。
上面的两种方法可是不仅可以用于后缀排序,还可以用于“给个字符串排序”啊。这不就相当于,“后缀”的条件完全没有利用上吗?那怎么可能做得出来啊。
“后缀”的条件是,这些字符串有很多的公共部分!利用这些公共部分,就能改善我们算法的时间复杂度!
利用这个条件的方法很多,像后缀树、后缀平衡树、后缀自动机等。当然,我们在这里要介绍的是最简单的一种——倍增法求后缀数组。
倍增法的主要思想是,“用排名代替具体的元素”。
我们用字符串"aabaaaab"做例子(这个例子好经典,为什么?因为它是 IOI 2009 国家集训队论文里边的啊~),它的后缀有"b","ab","aab","aaab","aaaab",'baaaab","abaaaab","aabaaaab"。
首先,我们把所有的后缀调整成一样长的,也就是(假装)我们在字符串后面补了一些空字符('\0',字典序是最小的;下面用0表示)。那么后缀就变成了"b0000000","ab000000","aab00000","aaab0000","aaaab000",'baaaab00","abaaaab0","aabaaaab"。补这些字符并不影响字典序,因为我们规定,比不出大小时短的字符串较小。
思考这个问题:某些元素,按双关键字排序的排名是,按双关键字排序的排名是,那么按四关键字排序的排名是否就相当于按双关键字排序的排名呢?(关键字的顺序表示主次顺序。)
思考后可以发现,答案是肯定的。
那么,我们就把这个字符串的所有长度为的块进行排序;接着把它所有长度为的块按照组成它的两个块的排名(在前面的是主要关键字,在后面的是次要关键字)进行双关键字排序,就可以得到块的排名;然后再把块按照块的排名进行双关键字排序,得到块的排名……直到块的长度不小于为止。此时每一个块都是原串的后缀(因为长度不小于,因此除了s[1...n],其余块都一定要越过s[n]补零,也就成了后缀),我们就得到了后缀的排序。
引用一下集训队论文里的图片——
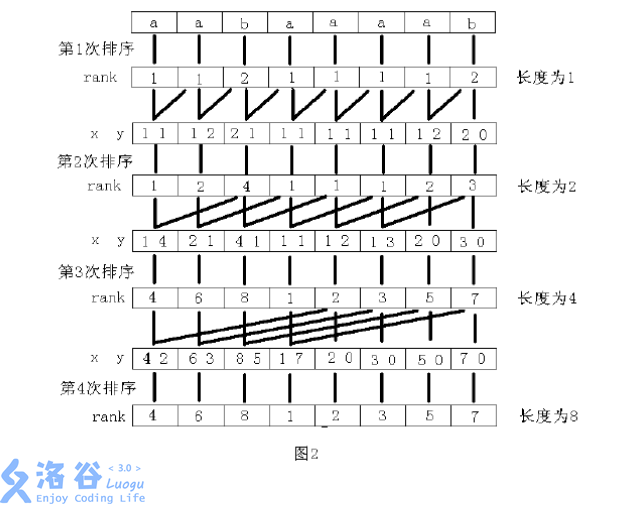
从图中我们可以看到,每一次排序都是把上次排序的rank数组作为元素值,也就是“用排名代替具体的元素”。排序的主要关键字是上一次的rank[i],次要关键字是上一次的rank[i+w],其中。
从图中我们还可以看到,我们不必实际地去补“0”,只需要在所找的块、块等超出边界的时候直接令他们的原排名为即可。
那么,我们就可以实现代码了。
首先是桶排序部分的代码。我们已经把次要关键字rk[i+w]的元素数组制作好并存到了数组tp里,因此相当于次要关键字已经排好序了。注意,sa和tp都是元素数组。
1 | void bucket_sort(int n,int m){ |
四重嵌套那一行可能比较难写。一个较为快速的推法是,把映射关系写下来,再根据映射关系写(“量纲分析”)。
- 要求出
sa,先写sa[ ]= sa的值是id,值是id的只有tp,写下sa[ ]=tp[i]sa的定义域是rank,值域是rank的只有bucket,写下sa[bucket[ ]--]=tp[i](是bucket,所以伴随着--)bucket的定义域是val,值域是val的只有rk,写下sa[bucket[rk[ ]]--]=tp[i]rk的定义域是id,值域是id的已知量只有tp,写下sa[bucket[rk[tp[i]]]--]=tp[i]。
接着再来实现后缀排序的主函数。
1 | void suffix_sort(int n){ |
通过这两个函数,我们就计算出了sa和rk数组,也就实现了后缀排序。输出sa数组就可以通过这道模板题了。
可能这里的注释还有一些不清楚的地方,但是暂时无法进一步完善了(哭)。如果有什么问题在评论区提吧。
那么这篇文章就结束了。